Back Story
I am a 25 year old male from the US, and I have been suffering from constipation, food sensitivities, insomnia, and psoriasis since 2018 (21 years old) after a round of Clindamycin.
This person actually has three samples from OmbreLabs:
- 2022-09-09: Firmicutes 95% (93%ile)
- 2022-10-01: Firmicutes 93.5% (88%ile)
- 2022-11-10: Firmicutes 94.8% (90%ile)
The first thing that I note is that “give it time, it will correct itself” does not seem to be happening. The second thing is these rates appear to be seen in about 10% of the samples.
Drilling down to which Firmicutes are dominating we have (latest sample):
- (order) Eubacteriales / (class) Clostridia – 75% (down from 85% in prior sample)
- Lachnospiraceae – 40% holding
- Ruminococcaceae – 21% (down from 33% in prior sample)
- Faecalibacterium prausnitzii -15.5% (down from 22%)
- (class) Bacilli – 13.5% (up from 3.4% prior)
- The list goes on an on!
My first impression is that we want to focus solely on reducing the high ones, and make room for the low ones to grow. That is actually a choice on building a consensus. Because of the shear numbers, I am going to use strict study citations. Why? Typically we are sparse on studies and need to infer / estimate likely impacts. In this case, we are going to hit studies everywhere!

For bacteria selection (with only highs) we have:
- Filter by Standard Lab Ranges – 14 bacteria
- Kaltoft-Moltrup Ranges – 50 bacteria
- Box Plot Whiskers Ranges – 58 bacteria
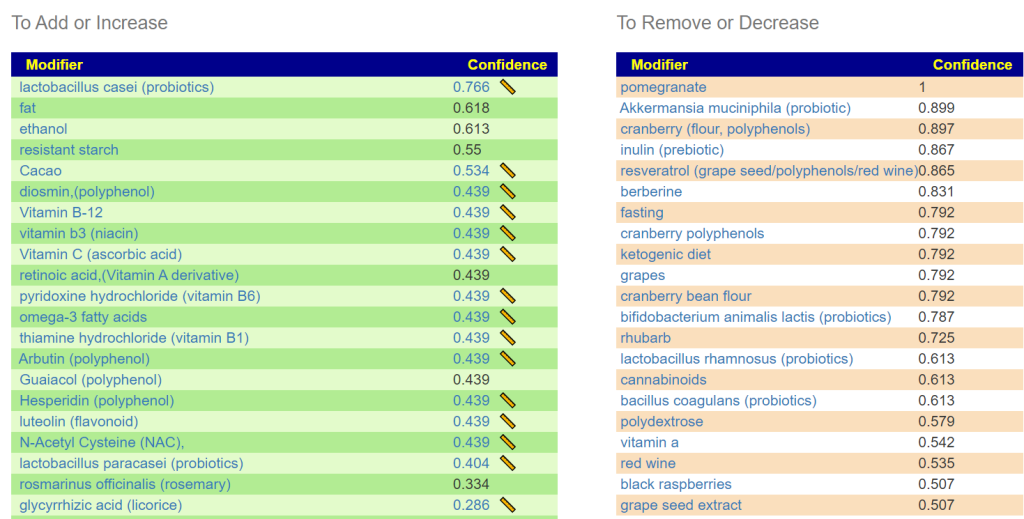
The list of items suggested is atypical with supplements dominating! I attach them below.
| Priority | Gut Modifier |
| 795.9 | Hesperidin (polyphenol) |
| 789.3 | melatonin supplement |
| 774.7 | luteolin (flavonoid) |
| 774.7 | retinoic acid,(Vitamin A derivative) |
| 774.7 | Arbutin (polyphenol) |
| 774.7 | diosmin,(polyphenol) |
| 774.7 | vitamin b3 (niacin) |
| 774.7 | pyridoxine hydrochloride (vitamin B6) |
| 709.2 | thiamine hydrochloride (vitamin B1) |
| 688.7 | vitamin b7 biotin (supplement) (vitamin B7) |
| 687 | N-Acetyl Cysteine (NAC), |
| 656.3 | linseed(flaxseed) |
| 642.7 | Vitamin B-12 |
| 592.7 | caffeine,(coffee or non-herbal tea) |
| 563 | tea |
| 522 | neem |
| 506.5 | quercetin,resveratrol |
| 495.6 | folic acid,(supplement Vitamin B9) |
| 455.7 | Guaiacol (polyphenol) |
| 438.6 | low carbohydrate diet |
| 428.5 | carboxymethyl cellulose (prebiotic) |
My suggestion would be a low carbohydrate diet and start taking the supplements above. I would avoid all probiotics, one did show up at the top of the probiotics: bifidobacterium longum bb536 (probiotics) at the strain level, but a strong avoid at the species level which means it is a high risk one

I would use the suggested dosages cited below (AFTER reviewing with your medical professional)
| Microbiome Modifier | CurrentDosage | Clinical Dosage | Est Confidence |
| Vitamin B1 Thiamine | 1.8 gm/day | 709.2 | |
| Vitamin B3 Niacin | 3000 mg/day | 774.7 | |
| Vitamin B6 Pyroxidine | 200 mg/day | 774.7 | |
| Vitamin B7 | 300 mg/day | 688.7 | |
| Vitamin B9 Folate | 5 mg/day | 495.6 | |
| Vitamin B12 Cyanocobalamin | 10 mg/day | 642.7 | |
| Vitamin C | 30 g/day | 410.7 | |
| Vitamin D | 50000 UI/day | 141.3 |
Questions From the Reader’s Review
In general, I avoid diet styles personally because they lack precision for the content. For example, does doing a Mediterranean diet means drinking the typical amount of wine (10-12 liters of wine per year) with 57 pounds of fish a year as seen by many countries around the Mediterranean? The fish consumption in the Mediterranean region differs greatly from what is claimed to be from that diet.

- What exactly is meant by a low carb diet in the research? (50 grams, 100 grams, etc)
- Low carbohydrate diet comes from the report of a single study: The Potential Roles of Very Low Calorie, Very Low Calorie Ketogenic Diets and Very Low Carbohydrate Diets on the Gut Microbiota Composition.[2021] This is a literature search. It cites: 800 kcal, carbohydrates 67 g, proteins 90 g, fats 9.5 g
- I see that sorghum is recommended despite being a carb source (this is further in the consensus suggestions, but on in the blog post), so would this be a high risk item?
- Suggestions are done independent of each other. In general, we have no idea about interactions. As with all suggestions, the source of the suggestion is available, in this case it was specific for sorghum brans [2015].
- Vegetable/fruit juice based diets is one of the diet styles recommended. Would perhaps following a diet low if solid carbs like rice, bread, potatoes but still consuming orange juice be an idea worth considering? Getting carbs from juices would essentially prevent any food residue from getting far into the digestive system; therefore, limiting fermentable residue. I am asking so much about carbs because I have done low carb in the past, and I felt better for a short period of time but worse long term.
- Again, this is based on a single study: Health benefit of vegetable/fruit juice-based diet: Role of microbiome [2017]
- From your description, I would look for what is in it and work there. The other issue is that most of the studies are short term.
- How long should the low carb diet be followed? How strict do I have to be to receive benefits?
- Suggestions are usually safe to keep to for 4-6 weeks, then their impact on the microbiome should be realized and a retest should be done to get the next course adjustment.
- How safe is carboxymethyl cellulose as a prebiotic based on the research? I am a little concerned about taking it. I also have a capsule making kit, so I would be able to make my own capsules.
- I would say it is fine for the 4-6 weeks cited above. The AI does not look at safety — just what is documented to change. You may wish to read the studies that were used:
- The in vitro Effect of Fibers With Different Degrees of Polymerization on Human Gut Bacteria. [2020]
- Acute Exposure to Commonly Ingested Emulsifiers Alters Intestinal Mucus Structure and Transport Properties. [2018] – especially for how much is deemed acute
- The Role of Carrageenan and Carboxymethylcellulose in the Development of Intestinal Inflammation [2017]
- I would say it is fine for the 4-6 weeks cited above. The AI does not look at safety — just what is documented to change. You may wish to read the studies that were used:
- Chitosan has a fairly high at 407.3 on the consensus. Is there a reason for not including it on your list in the blog post. I see that one of your posts from CFS remission seem to recommend it for firmicutes overgrowth.
- The reason to include or exclude is actually shown on the Advance Tab, see below
Getting the Reasons for Suggestions
- Change Display Level to Advance
- Go to Research Features tab
- Find this section and click Advance Suggestions

On the next page select how you want to generate suggestions and then make sure you click the green box

On the next page you will see book stacks (?) by each suggestion.
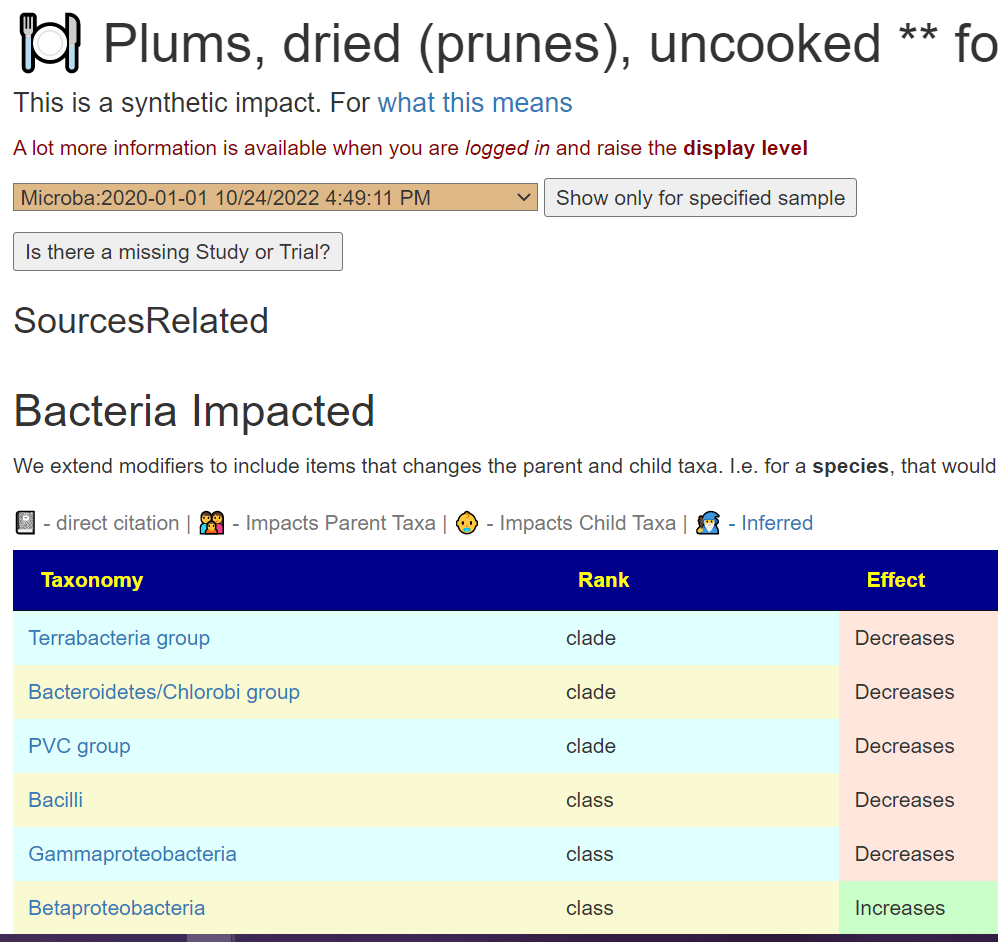
Click it:
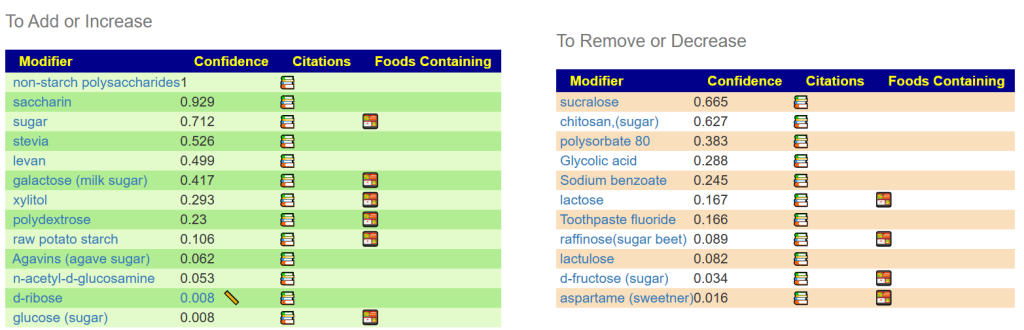
This will show the studies used to make this decision and why. That is, what are the other bacteria impacted by using this chitosan. Note that there are 42 taxa-studies listed! Focusing on a single bacteria, like firmicutes is not a process that I encourage, that is why I let the AI determine the suggestions based on all of the facts available.

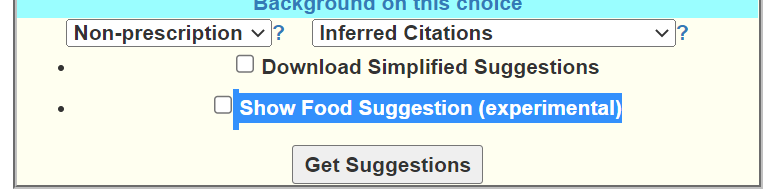
Foods
If you pick a diet type, then using the new experimental food component would be suggested as an adjunct tool. I used the KM filter, restricted only to high bacteria as a start point for foods.
At the bottom of the suggestions page, we see the link button
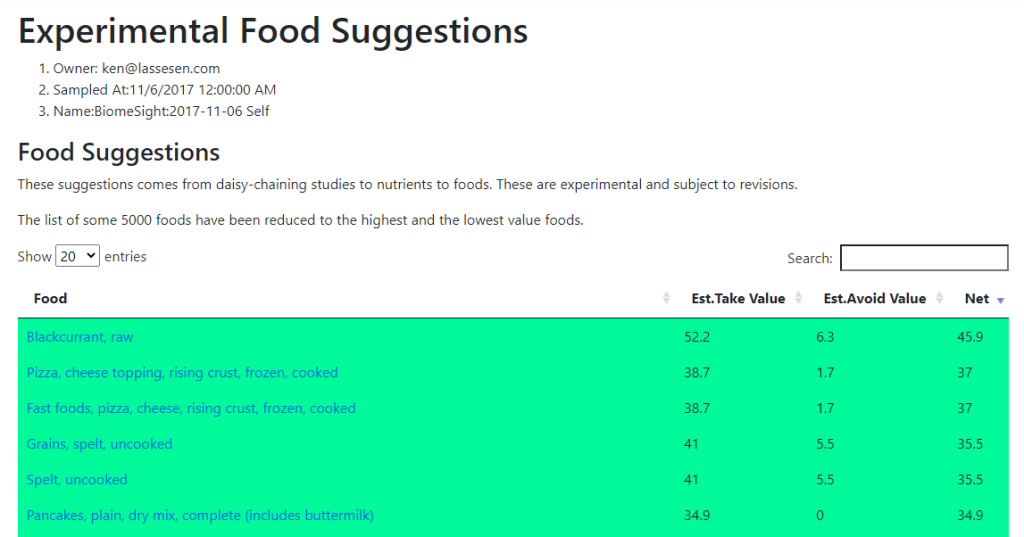
The top items (with nutrients they were selected on) are listed below:
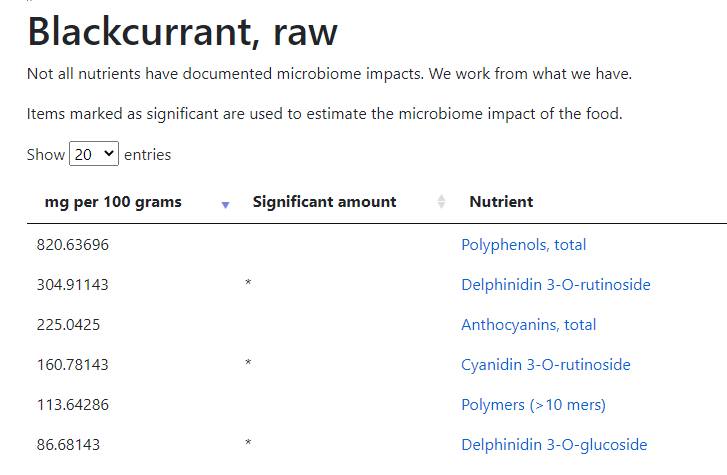
- Walnut: Valoneic acid dilactone, Myricetin
- Rye, grain, whole, uncooked, Flour, rye: Fiber, total dietary, Inulin, Magnesium, Mg, Starch
- Artichoke, jerusalem, peeled, boiled, drained: Raffinose, Inulin
- Corn, white, steamed (Navajo): Starch, Fiber, total dietary, Magnesium, Mg
- Lentil, red, hulled, dry: Starch, Fiber, total dietary, Inulin
On the avoid list:
- Tea, instant, unsweetened, lemon flavour, powder: Caffeine, Potassium, K
- Orange [Blond], Limes: Hesperetin which includes
- Peppermint, dried, Bitter Orange, Buchu
- Garlic (fresh): Pyridoxine (Vitamin B6
- Other foods high in this.
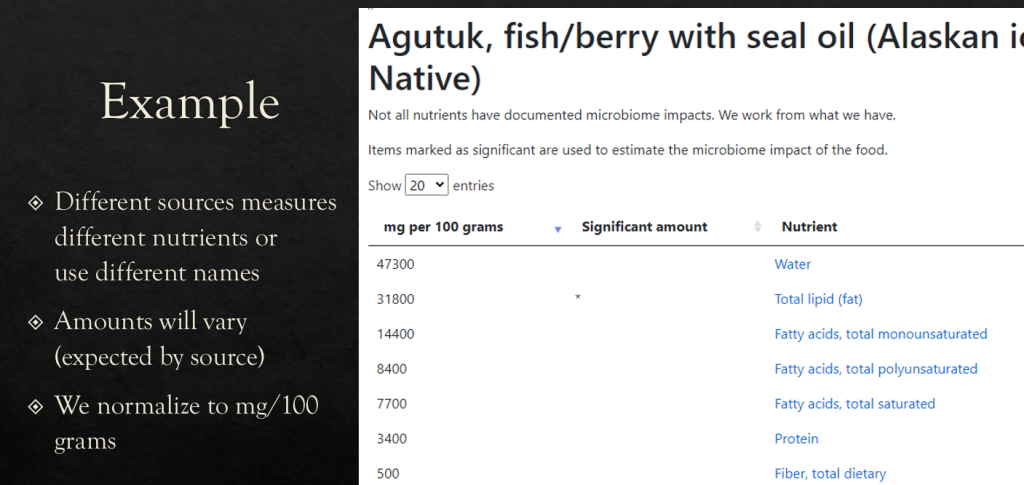
The food list takes items like Hesperetin and vitamins, and show the foods higher than typical. It speeds the analysis (and also overload the data that you have).
Postscript – and Reminder
I am not a licensed medical professional and there are strict laws where I live about “appearing to practice medicine”. I am safe when it is “academic models” and I keep to the language of science, especially statistics. I am not safe when the explanations have possible overtones of advising a patient instead of presenting data to be evaluated by a medical professional before implementing.
I cannot tell people what they should take or not take. I can inform people items that appears to have better odds of improving their microbiome as a results on numeric calculations. I am a trained experienced statistician with appropriate degrees and professional memberships. All suggestions should be reviewed by your medical professional before starting.
I use modelling and various mathematical technique to estimate forecasts when there is no hard data available.
The information above should always be considered/discussed with your medical professional if possible.








Recent Comments