Saying “gluten is bad for you” is the same as saying the “bacteria are bad for you” (or “vitamins are good for you”. In some cases bacteria can be good for you, i.e. probiotics. Some vitamins can be bad, for example, “Vitamin D Toxicity“[2022]. These are over simplification and sweeping generalizations. To me, they are akin to saying “Blacks are criminals”, “Irish are drunkards”, and “Italians are part of the Mafia”.
”Gluten is a complex mixture of hundreds of related but distinct proteins, mainly [in wheat] gliadin and glutenin. Similar storage proteins exist as secalin in rye, hordein in barley, and avenins in oats and are collectively referred to as “gluten.” ” What is gluten? (US National Library of Medicine)
Barley is free of glutenins and gliadins, the troublesome glutens. You may be using “All black men are criminals” reasoning. You really need to be tested for which types of gluten proteins you reactive to and not go for internet-legend that all glutens are bad.
YES – you may feel better eating gluten free, but the why is more likely to be a wheat allergy than gluten issue!
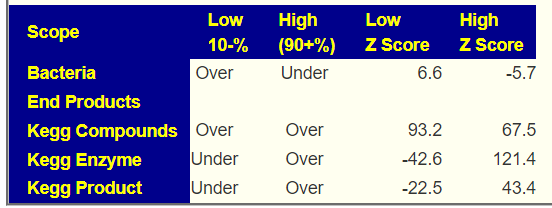
Looking at how the microbiome is influenced by barley, oats, rye, and wheat we see major differences –– which I ascribed to the chemical difference of the type of gluten in each. In most western diet, many items described as “Rye Bread” contain wheat, an example is below. People react to it and thus associate rye (the labelling) to problems.
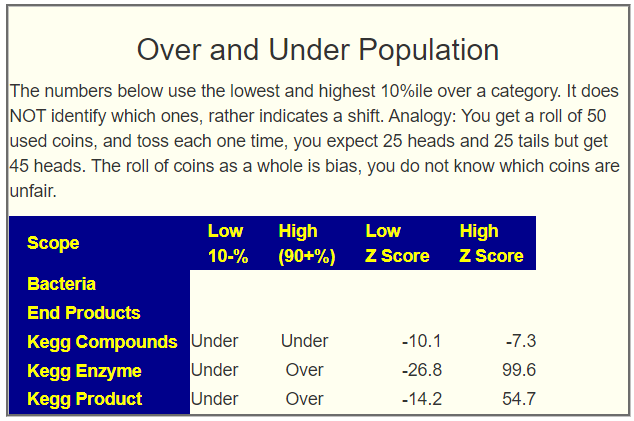
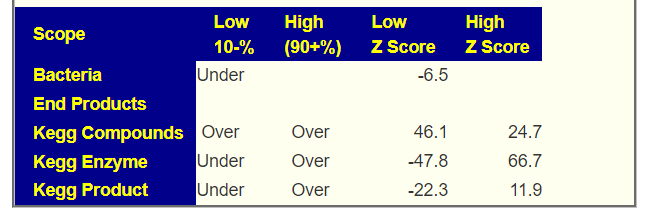
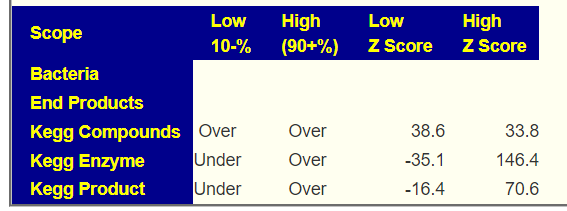
An example, Barley increases Ruminococcus according to 3 studies while wheat decreases it. For Clostridium botulinum: Barley and wheat increases while rye decreases. While a gluten free diet is reported to decrease both of these bacteria.
Bottom Line
You really should be tested for each type of gluten (even if your diagnosis is celiac disease). Going completely gluten free may make correcting a microbiome dysfunction a lot harder. Less than 1% of the population has a medical need to go gluten free [2018]. It is well sold by influencers on the internet.
“Gluten-free diets have soared in popularity in recent years. But, shunning gluten has no heart benefits for people without celiac disease, and it may mean consuming a diet lacking heart-healthy whole grains, according to the quarter-century study.”
Eating Gluten-Free Without a Medical Reason? WebMd,
A 2018 study lists the following risks of doing it without a proven medical need:
| Potential Harms of a GFD |
|---|
| Deficiencies of micronutrients and fiber |
| Increases in fat content of foods |
| Hyperlipidemia |
| Hyperglycemia |
| Coronary artery disease |
| Increased financial costs |
| Social impairment or restrictions |
GF has a higher frequency of osteopenia and osteoporosis than in controls has been reported [2014]
A 2021 study reports “the currently available gluten-free products in the market are generally known to be lower in proteins, vitamins, and minerals and to contain higher lipids, sugar, and salt compared to their gluten-containing counterparts…. Some studies have shown that commercialized gluten-free food products are often not gluten free. “
in Efficacy of Popular Diets Applied by Endurance Athletes on Sports Performance: Beneficial or Detrimental? A Narrative Review [2021] “when applied to non-celiac athletes, [Gluten Free] can create a large energy deficit and low energy availability, impairing both metabolic health and performance.” This is of especial concern when a symptom prior to going GF is tiredness.
“Beware of influencers!” Often they get big bucks for selling a concept to you!




%7D%7BN%7D%7D%7D&bg=ffffff&fg=000000&s=0)
Recent Comments