Back Story
Born premature 25 weeks ivf pregnancy on tons of hormones for myself. Vaccines for her. Can’t poop on her own. Gi maps test showed clostridia, strep, entero faec etc. Mycotox urine kit showed 2 most toxic molds citrinin ocratoxin a, fatty acid oxidation issues, methylation issues, mthfr, double slow comt gene, reactions to most foods (behaviors),restless sleep. Autism diagnosis. She is 6 years old now.
Analysis
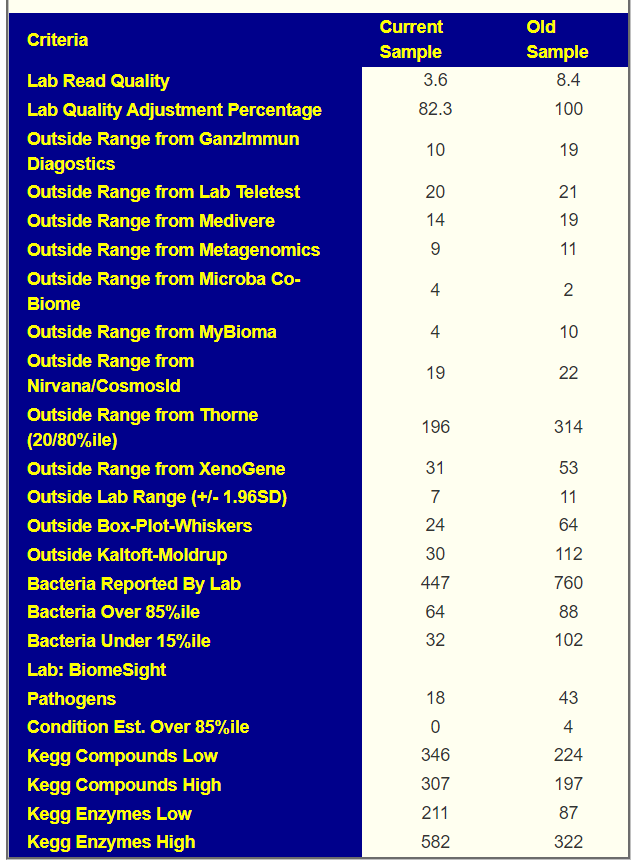
I always approach under 15 y.o. with caution because they are very understudied, and the existing studies show major changes from adults.
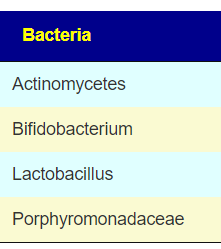
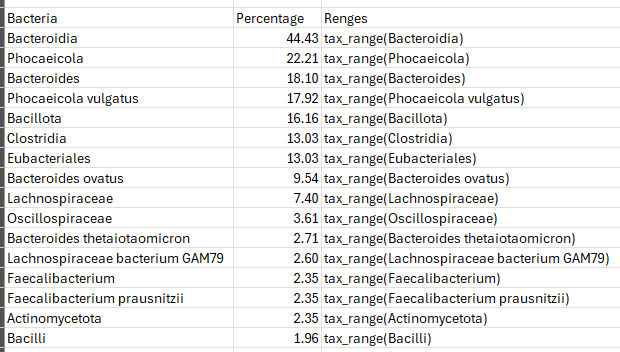
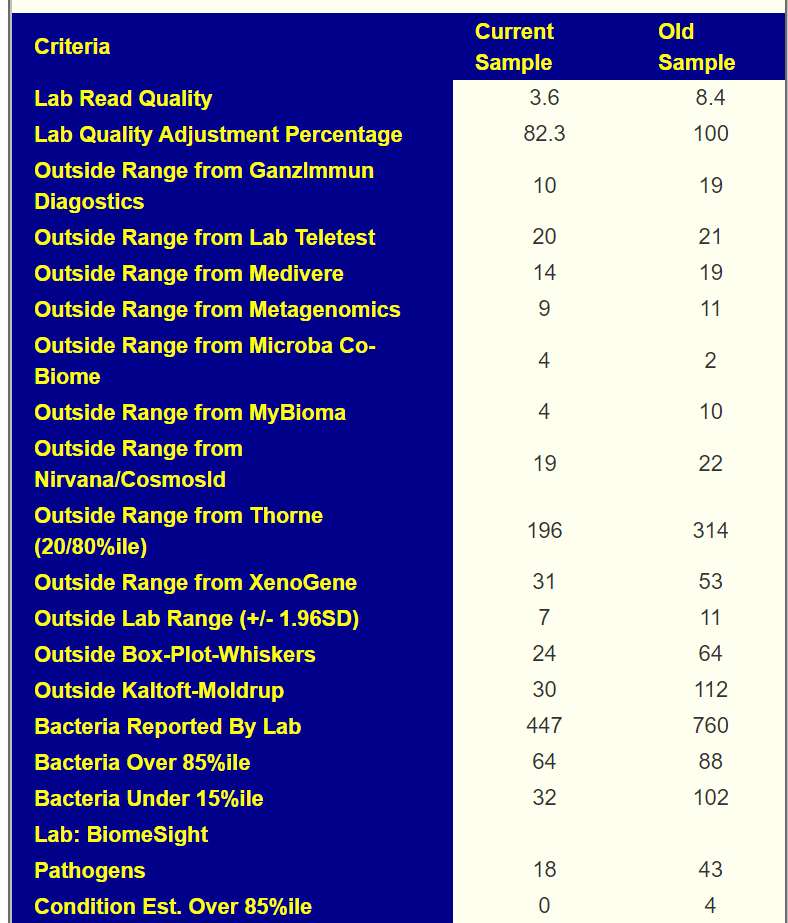
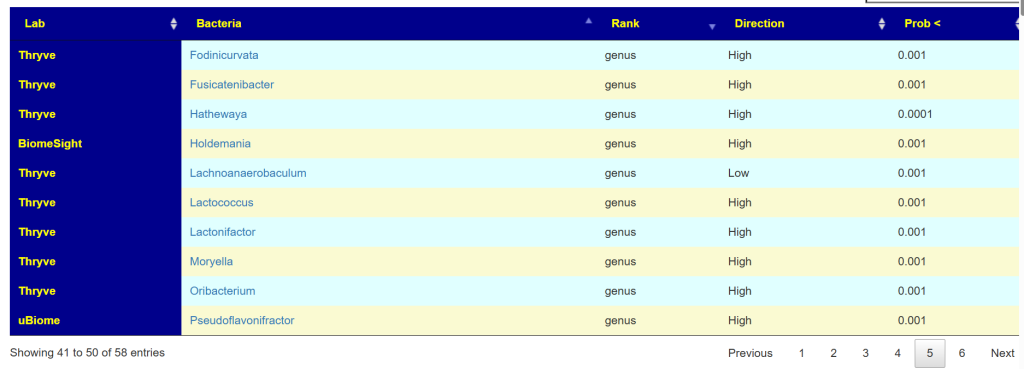
Key Bacteria identifies two species:
- Bacteroides uniformis (95%ile)
- Akkermansia muciniphila (98%ile)
I then checked some literature: Commercial microbiota test revealed differences in the composition of intestinal microorganisms between children with autism spectrum disorders and neurotypical peers [2021]
- “Other microbes observed in large quantities in the feces of ASD compared to neurotypical children include such species as Akkermansia muciniphila “
- For Bacteroides uniformis, there was no clear literature associated.
I then went over to look at typical items from the literature.
- Bifidobacterium: 34%ile, well below expected levels for a child. See A comparison between children and adolescents with autism spectrum disorders and healthy controls in biomedical factors, trace elements, and microbiota biomarkers: a meta-analysis [2023] “children with ASD had significantly iron and zinc , lower relative abundance of Bifidobacterium and Parabacteroides and higher relative abundance of Bacteroides” (see above on Bacteroides uniformis, Bacteroides fragilis is also high at 84%ile). Parabacteroides is at 63%ile.
Going Forward
It will be just a “give me suggestions” plus some suggestions that are typical for autism. In general, I try to cross validate the suggestions with the current literature on Autism. Example: Go to https://pubmed.ncbi.nlm.nih.gov/, enter the item and autism and see if there is any literature.

In this case, one result was returned (a bit of a heavy and twisted read).
“luteolin and diosmin inhibited neuronal JAK2/STAT3 phosphorylation both in vitro and in vivo following IL-6 challenge as well as significantly diminishing behavioral deficits in social interaction. Importantly, our results showed that diosmin (10mg/kgday) was able to block the STAT3 signal pathway; significantly opposing MIA-induced abnormal behavior and neuropathological abnormalities in MIA/adult offspring.”
Flavonoids, a prenatal prophylaxis via targeting JAK2/STAT3 signaling to oppose IL-6/MIA associated autism [2009]
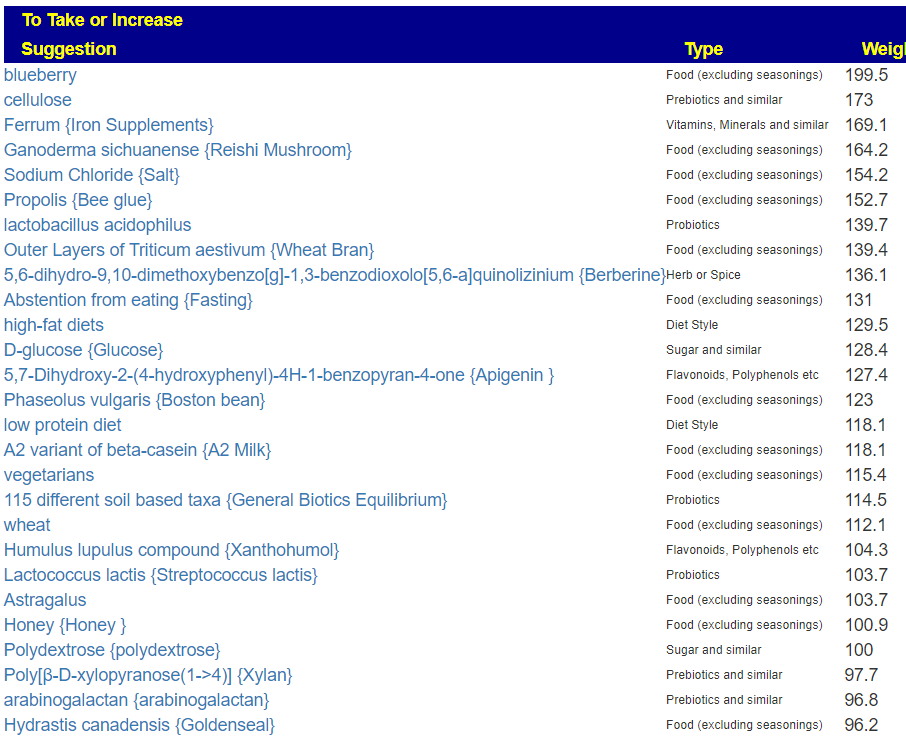
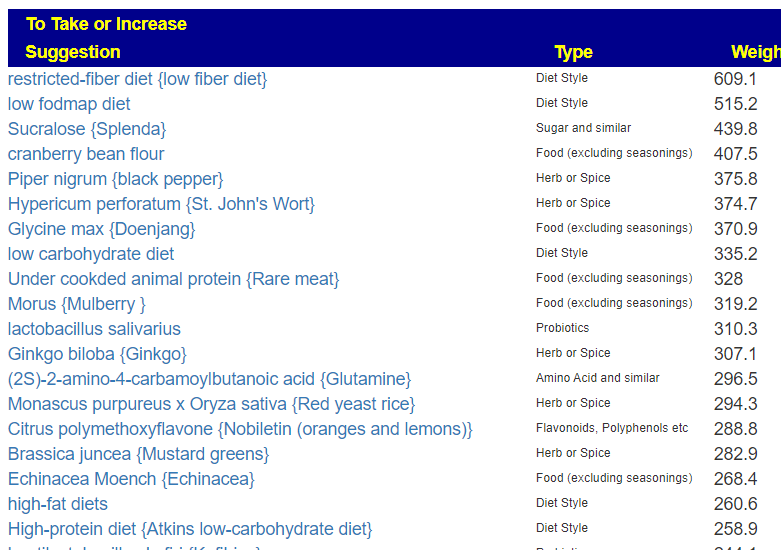
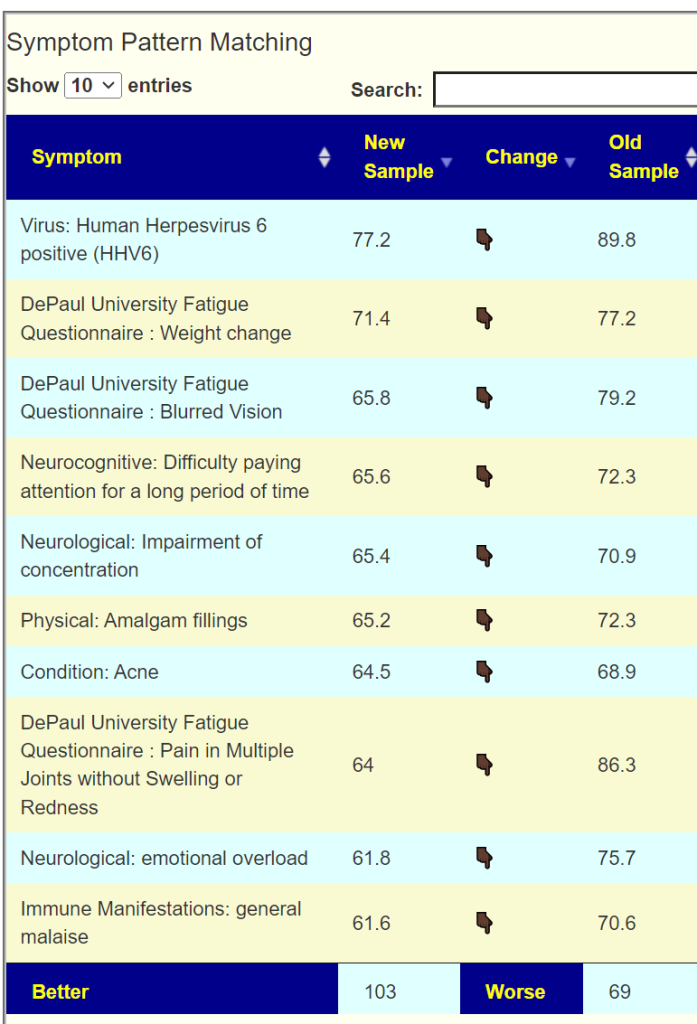
I have done a few, but the reader should check each one. Items that cross-validate should be choice #1, other items as a secondary choice.
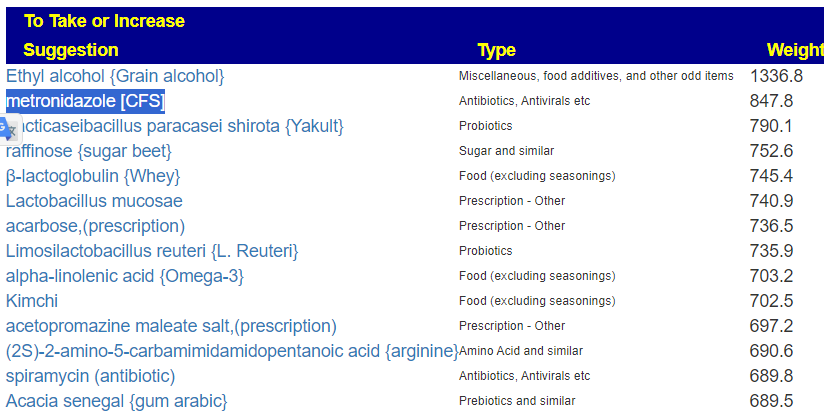
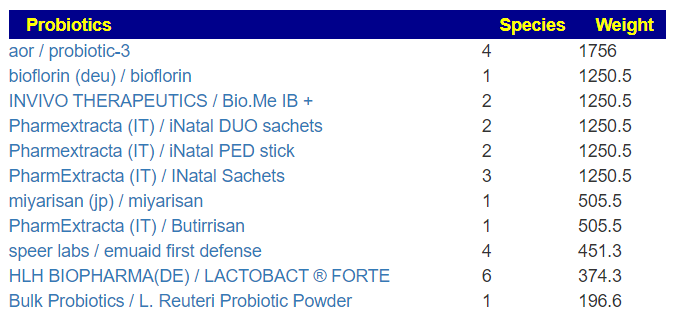
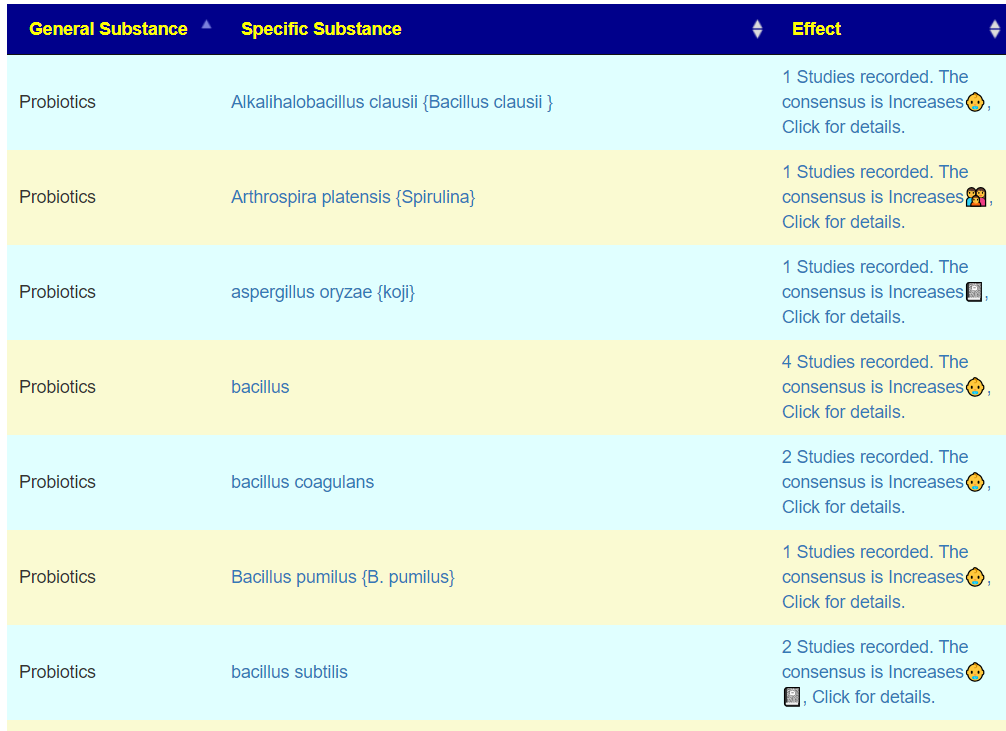
- Probiotics
- bifidobacterium infantis,(probiotics) was high on the list, which is to be expected with autism.
“participants on both treatments saw a reduction in the frequency of certain GI symptoms, as well as reduced occurrence of particular aberrant behaviors.” [2019] - lactobacillus casei (probiotics)
- lactobacillus reuteri (probiotics) – “However, L. reuteri combination yields significant improvements in social functioning [in autism] that generalized across different measure” [2023]
- clostridium butyricum
- See Effects of Probiotics on Autism Spectrum Disorder in Children: A Systematic Review and Meta-Analysis of Clinical Trials
- bifidobacterium infantis,(probiotics) was high on the list, which is to be expected with autism.
- Supplements:
- Foods
- whole-grain barley (i.e. morning porridge)
- walnuts
- whey
- Pineapple
- brown rice
- sucralose (as preferred sugar)
- Herbs and Spices – possibly as teas
Postscript – and Reminder
I am not a licensed medical professional and there are strict laws where I live about “appearing to practice medicine”. I am safe when it is “academic models” and I keep to the language of science, especially statistics. I am not safe when the explanations have possible overtones of advising a patient instead of presenting data to be evaluated by a medical professional before implementing.
I cannot tell people what they should take or not take. I can inform people items that have better odds of improving their microbiome as a results on numeric calculations. I am a trained experienced statistician with appropriate degrees and professional memberships. All suggestions should be reviewed by your medical professional before starting.
The answers above describe my logic and thinking and is not intended to give advice to this person or any one. Always review with your knowledgeable medical professional.











Recent Comments