I was first aware of Human Milk Oligosaccharides (2′-Fucosyllactose) being used for health back in the 1960’s. How? Chairman Mao! Let me explained, Mao cites the case of nursing mothers having their child removed so that the mom could literally be milked for the benefit of the warlord’s health. An extreme way of getting HMO — not recommended!!!
I do not recommend any specific brand — because there have been no studies clarifying the differences between brands, hence no clear evidence on which one is superior for specific conditions. I was first introduced to HMO as a supplement via Holigos, a Danish firm (being of Danish heritage, I was likely biased!) and had several conference calls with their researchers back in 2018 when the first clinical trials were being done in the US.
Needless to say, there are now a few suppliers on the market (I have excluded ‘polluted‘ products, i.e. products mixed with other ingrediants)
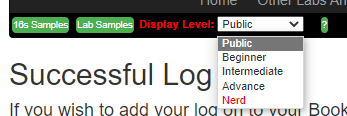
Based on requests from users, we have implemented display layers to reduce the problem of information saturation reported by some users.
The following levels control what you see on menus and what is hidden
Public— Least items, just the bare essentials
Beginner— More items, you must be logged in to see these items
Intermediate— More choices, you must be logged in to see these items and be a premium member
Advance— Almost all choices. Logged in and be a professional member
Nerd— All choices, Logged in as a professional and requested access to research items to see these items and be a professional member.
Often these items require an advance understanding of the microbiome processes and behaviors
AFTER logging in to Microbiome Prescription, you will see a select box to set your display level. Red items indicate level is not available for your login level. See this page for more information about login level. And this page on why you may wish to donate.
Example of choices with PublicExample after logging inShown without a loginAfter Login with a high display levelBacteria Information with public display levelExample of Bacteria Detail Page with high display level
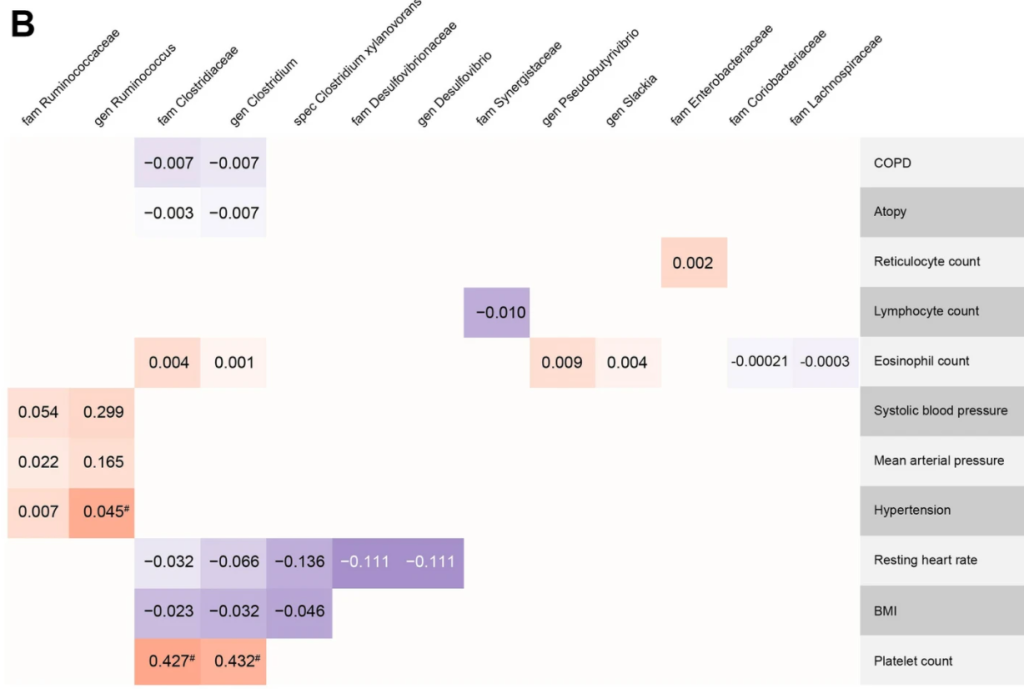
It is one of the factors. Diet is also a factor. Today, there was some sweet studies published on Nature. A few quotes are below.
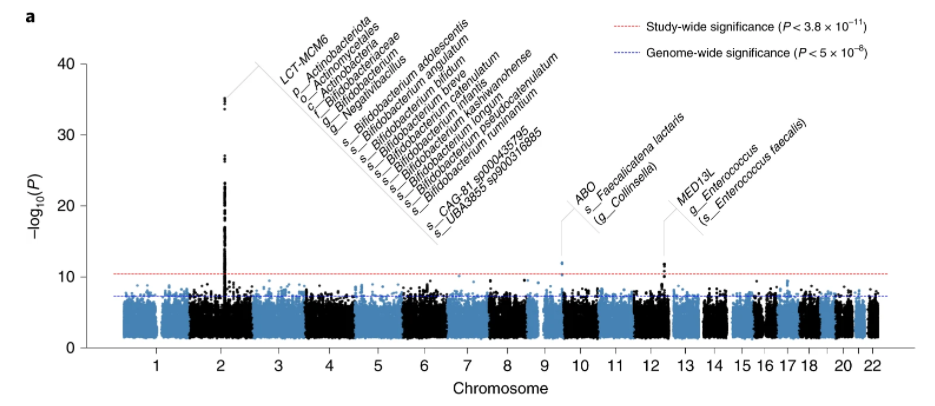
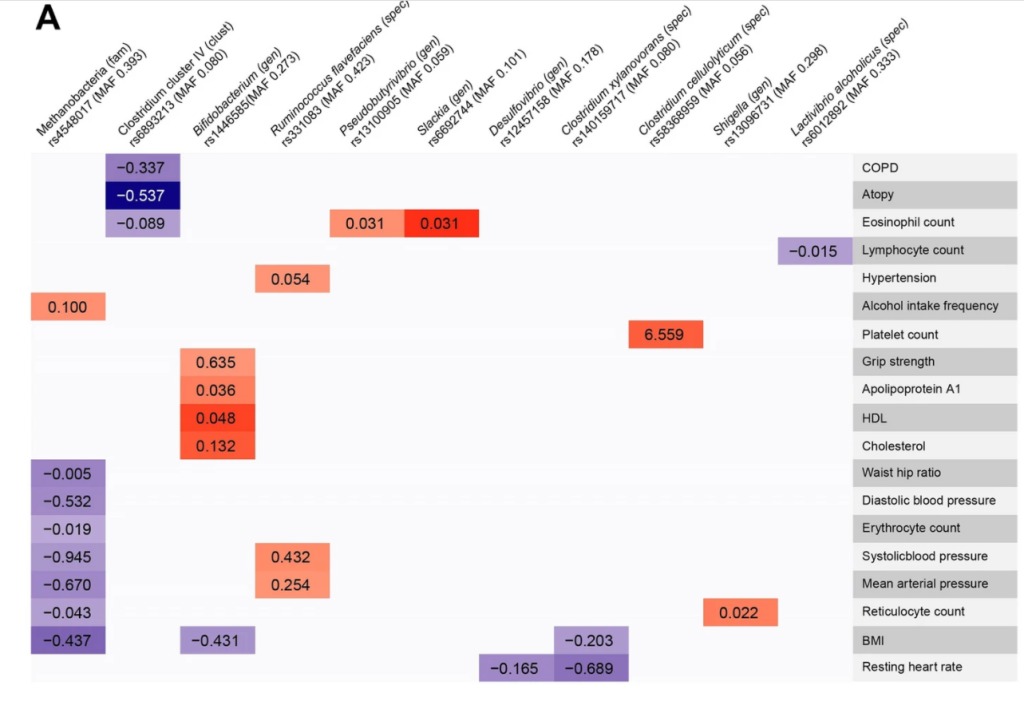
Variants at the LCT locus associated with Bifidobacterium and other taxa, but they differed according to dairy intake. Furthermore, levels of Faecalicatena lactaris associated with ABO, and suggested preferential utilization of secreted blood antigens as energy source in the gut. Enterococcus faecalis levels associated with variants in the MED13L locus, which has been linked to colorectal cancer. Mendelian randomization analysis indicated a potential causal effect of Morganella on major depressive disorder, consistent with observational incident disease analysis
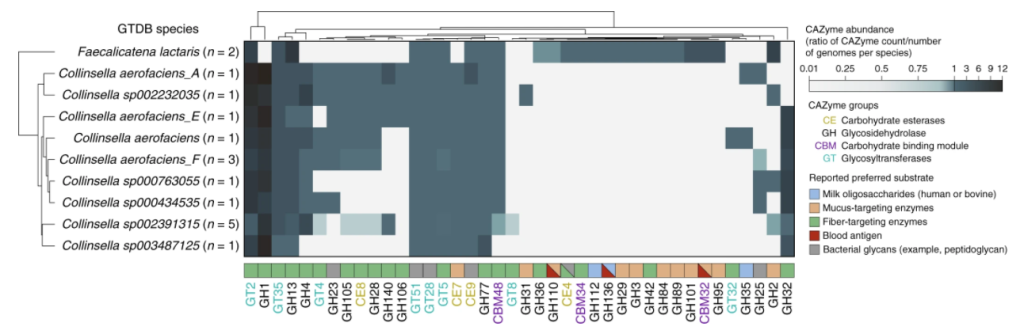
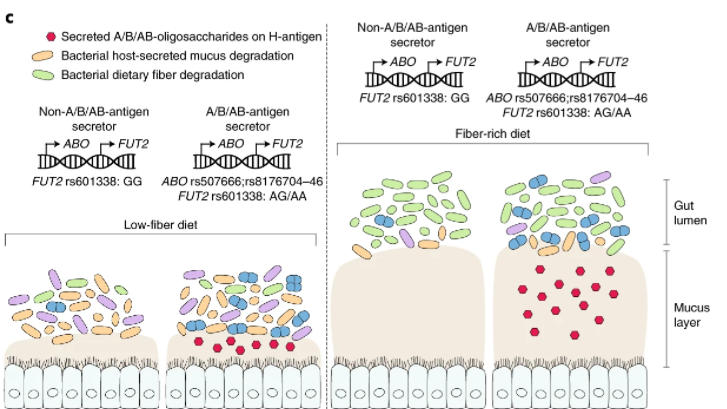
Our associations of F. lactaris (P = 1.10 × 10−12) and Collinsella (P = 2.59 × 10−8) with ABO suggest a possible metabolic link with blood antigens.
In our study, as in previous work3,5,6,10, the association of LCT variants with Actinobacteria, more specifically Bifidobacterium, is by far the most statistically significant
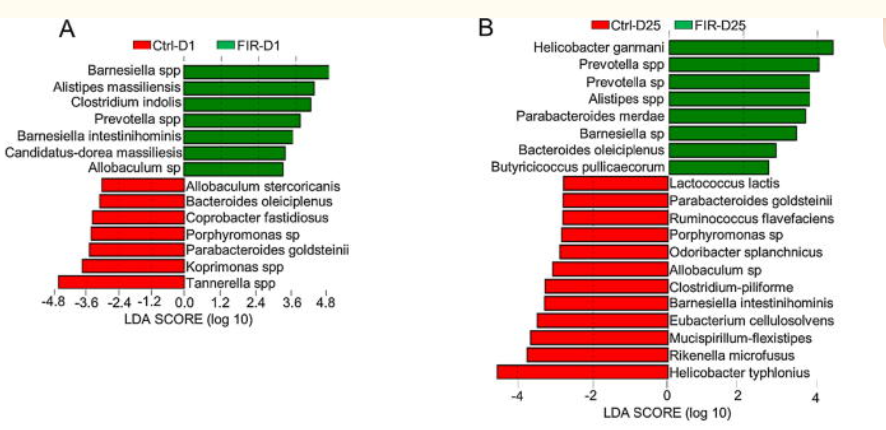
This is well illustrated by this chart in the above study
This study illustrate how the presence or absence of some bacteria species depends on the individual’s DNA as shown in the chart below.
Note: F. lactaris was formerly known as Ruminococcus lactaris (it is reported on Ombre and Nirvana/Cosmos results)
They went onwards and show how diet compounds matter more.
This information has been hinted at in earlier studies:
“association of a functional LCT SNP with the Bifidobacterium genus (P = 3.45 × 10-8) and provide evidence of a gene-diet interaction in the regulation of Bifidobacterium abundance. ” [2016]
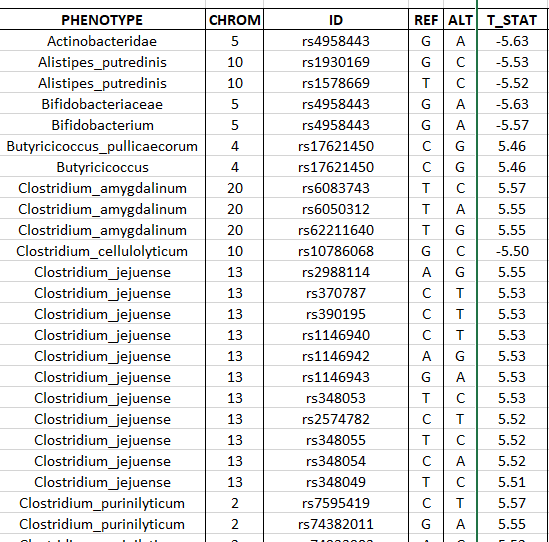
We are still in early days, in some cases you may be able to find studies on PubMed by searching for “SNP {bacteria name}”, for example: “SNP clostridium cellulolyticum” or a google search on similar terms. From which I found:
Your body is like a brand new car, everything runs perfectly (assuming no factory recalls). You drive it all over the place and happy with using it. One day, you park it and a stranger’s car hits it (the infection) and knocks it into a ditch filled with water.
The car is recovered from the ditch, taken to a body shop and a local service station mechanic to fix the damage and make sure everything runs. These are the physicians of the car world.
On your next trip over the mountains, pulling your usual vacation trailer, you find a ton of symptoms with the car:
You smell something, is it mold? is it oil smoking?
The car does not pull the trailer as easy as before, flooring the gas pedal gets you up to just 20 miles per hour where you did 50 miles per hour before
You hear creaks when some doors open
One window occasionally will not go up or down (but does it whenever it is in the shop)
Some warning lights flashes on for a while and disappear
A car expert comes in. Almost disassemble the car totally! He discover a massive list of issues caused by earlier events:
The insulation on the electrical system cables has been damaged, circuit boards no longer work to specification, you may need to have all of it replace…
There is an oil leak
There is a slow leak of the radiator, hence the engine warning lights occasionally come on
There is mold behind the panels and under the carpets
Corrasion is starting on the brakes lines
and the list goes on and on.
You go to your insurance company (almost like Medical Insurance) and find there is only a little coverage. They look at the cost of fully fixing the car, and realize that is far above the blue book value. In fact, they claim that some of issues occurred while the car was insured with a different company, hence they are not responsible (“pre-existing condition”).
In some cases, like some onboard computers, replacement (treatment) is not available or deemed experimental. For example, a fecal matter transplant from a suitable donor.
You walk into your usual local car mechanic (family MD) with the list of items to fix. He looks at you with a blank stare. You may hear one of the following:
You really don’t need to fix all of those items, I will change the air filter for you and we’ll see how it will run…
I can’t fix those things. You are just tossing away money
How much money are you willing to spend, I will try fixing them — no guarantees
That’s the way it is with older cars, it’s natural!
A human is far more complex than a car. A lot of the issues trace back to the residue from the accident, the microbiome shifts. Some issues can be fixed (for example, removing moisture before consequences happen), some issues may persist (like wheel alignments), others can be ameliorated (for example, perhaps using higher octane gas).
The common mistake is to assume that fixing the dented front fender is all the repair that is needed. This problem is more complex because we are just the drivers (and owner) of the car — but know little about how it functions.
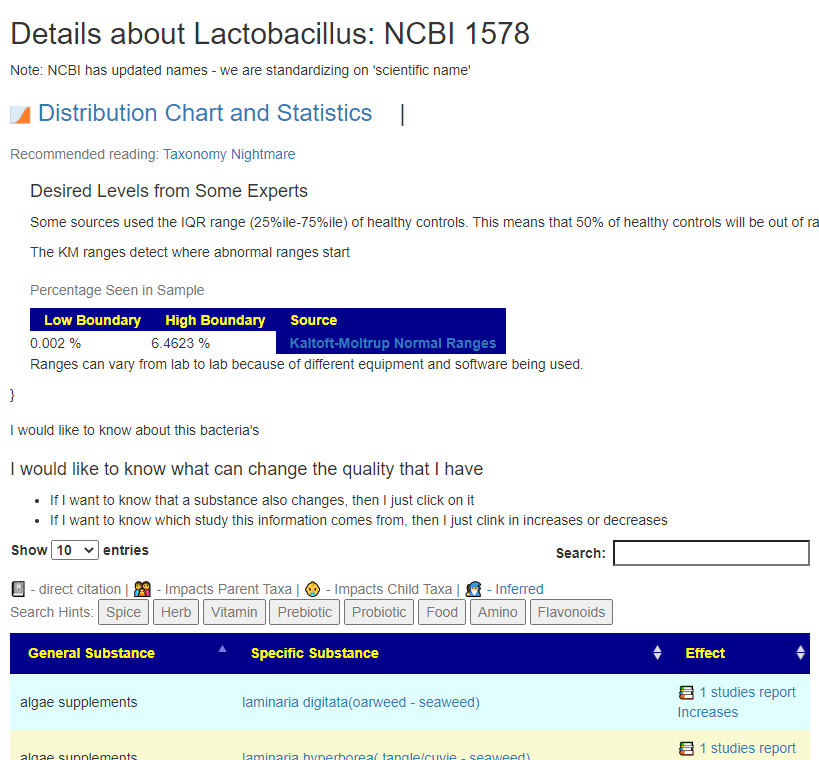
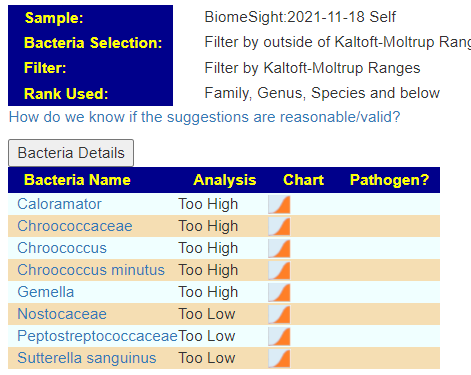
BE VERY CARFUL ACCEPTING Lab ranges for “normal” or if they show an “average” and leaves you to interpret (more likely misinterpret).
One of the things that I have discovered is that often the numbers are NOT a normal curve or a bell curve. Averages and ranges using standard deviations are… well.. the same as saying that the earth is flat. (That use of averages and standard deviation is the standard process for many lab tests – it does not work for the microbiome)
Look at Statistics and Distribution for Prevotella(genus)… It calculates ranges using the KM algorithms…YOU SHOULD NAG THE LAB TO DOCUMENT HOW THEY CALCULATE THEIR RANGES AND THE JUSTIFICATION FOR SHOWING AVERAGE…
You may need a respirator for the amount of smoke that they send your way
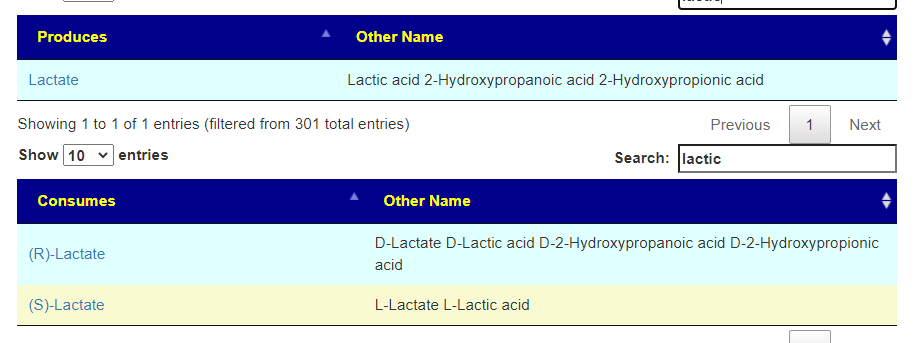
For literature on D-Lactic Acidosis see these posts: [2019] [2015] [2019] or
Increased D-Lactic Acid Intestinal Bacteria in Patients with Chronic Fatigue Syndrome [2009] “This study suggests a probable link between intestinal colonization of Gram positive facultative anaerobic D-lactic acid bacteria and symptom expressions in a subgroup of patients with CFS. Given the fact that this might explain not only neurocognitive dysfunction in CFS patients but also mitochondrial dysfunction, these findings may have important clinical implications.”
There are two approaches that could be used to make this determination:
Growing the probiotic is a mono-culture environment and measuring it. This is the traditional approach.
Examining the genes and see if any contain d-lactic acid producing enzymes
I favor the second approach because there can be issues with the reliability of the first one. Some bacteria shift production of metabolites, such as d-lactic acid, based on the availability of food, supplies, other metabolites in the environment (look up quorum sensing) etc. To give a human analogy, a human blacksmith will make iron ploughs but in a war situation, they may switch to guns, spears or armor.
Using the genes approach, we know what they are capable of making (not necessarily what they are making in a specific environment). In the case of the black smith above, his shop may be incapable of casting cannons.
Some 3 years ago, in this post I update my earlier post from 2013 and cited “, it is my hypothesis that this alters the microbiome — how, has still to be reported. “. There has been no objective impact on the human microbiome reported yet :-(.
Assuming that depression is partially microbiome caused (see this list of bacteria shifts seen with depression) then we have circumstantial evidence that they are changes (but do not know the details in humans). We do have information from one study on mice (see bottom of post)
” FIR requires modulations of janus kinase 2 / signal transducer and activator of transcription 3 (JAK2/STAT3), nuclear factor E2- related factor 2 (Nrf-2), muscarinic M1 acetylcholine receptor (M1 mAChR), dopamine D1 receptor, protein kinase C δ gene, and glutathione peroxidase-1 gene for exerting the protective potentials in response to neuropsychotoxic conditions.”
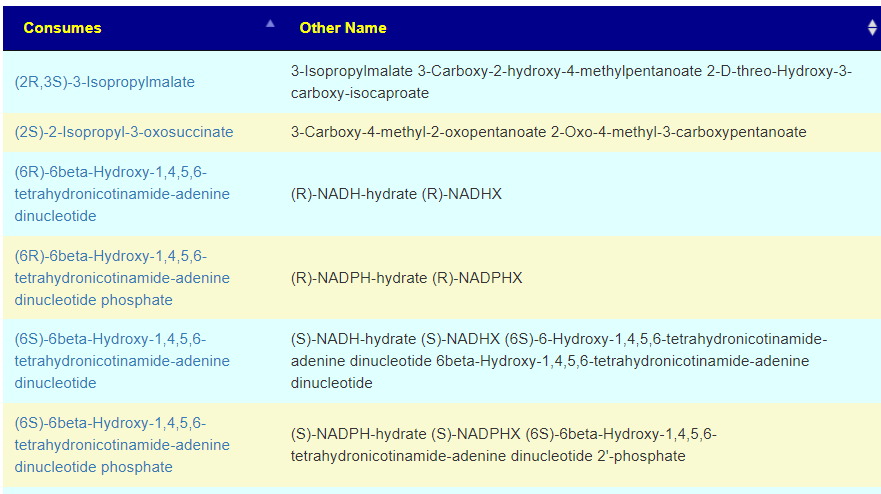
A reader of that page presented me with a challenging question: “Which probiotic would reduce ….. ?” I checked the US National Library of Medicine studies — nothing. I am a lateral thinker (read Edward de Bono since I was a teenager) and it occurred to me that, theoretically, we can use data from KEGG: Kyoto Encyclopedia of Genes and Genomes because they have the gene sequence of many probiotics and thus their enzymes. Enzymes are mini-factories that consumes some metabolites and produces other metabolites. There are 5200+ different compounds reported on KEGG.
Since I have all of the data in a friendly (to me) datastore, it was just a matter of constructing a few complex queries and creating some web pages. The result was this page: Probiotics to Change KEGG Compounds
In the video below, I walk thru how we use OATS result and this page. Other test results can be used. OATS happened to be inspiration for this feature.
I am a 26 year old male living in Germany. I have a M. Sc. iIn 2018, I did a semester abroad in St. Petersburg, Russia, and during the exam period got IBS. I think stress and/ or vegan diet, which I only tried for a few months, played a role. Extremely low Vitamin D was found, but nothing else.
I developed a lot of food intolerances since then.
In April 2021 I got a Biontech vaccination, and in the following days, noticed that I was tired all the time. It did not get better. I was barely able to finish my Masters Thesis as it was almost finished, but could not start working. Long story short, I now have a lot of the common CFS symptoms, additionally my hair fell out and low testosterone was found.
From a reader
Some technical notes: It cannot be diagnosed as CFS because it has not lasted long enough. It can be viewed as post-immune reaction syndrome. Second, I too have concerns about post-immune reaction syndrome this year, to explain why:
Three COVID 19 vaccinations
Tetanus vaccination
Pneumonia vaccination
Two Singles vaccinations
After each, I saw my system “act up”, Some measurable — such as a jump in blood pressure that took a couple of weeks to calm down. More often, i was dragging for a couple of weeks. Night Sweats. skin inflammation, etc.
To Vac or Not to Vac — that is really not the question. It is equivalent to saying “I will not wear a seat belt in case the car plunges into a lake and traps me in the car” The risk of that happening is very low compare to the risk of not wearing a seat belt. There is no rationality that can supported by rational analysis.
Some studies showing that vaccination does alter the microbiome.
Human studies have likely not been done because they will be misused by “anti-vaccination” people. We can be confident that changes will happen. The nature of the change will depend on the prior state of the microbiome – an unstudied area. The change from each vaccine will likely be different.
I should mention that I have read several personal reports of major improvement of microbiome conditions as a result of vaccination. A percentage may go either way.
Where do we go from here?
We have 3 sets of microbiome changers – stress, IBS and vaccination. Food intolerance was something of interest — alas, I could not find anything on PubMed that identifies bacteria associated with it. Doing a quick scan of my Biome View, nothing really stood out.
My general impression is that our list of usual suspects is really not there,
Time to Beat the Bushes
KEGG Generated Suggestions
The Weights were all below 20 — i.e. marginal, with Sun Wave Pharma/Bio Sun Instant, being the best of the short list
Similarly the supplement list was short at 10%ile and none at 5%ile
beta-alanine
D-Ribose
L-Histidine
Molybdenum
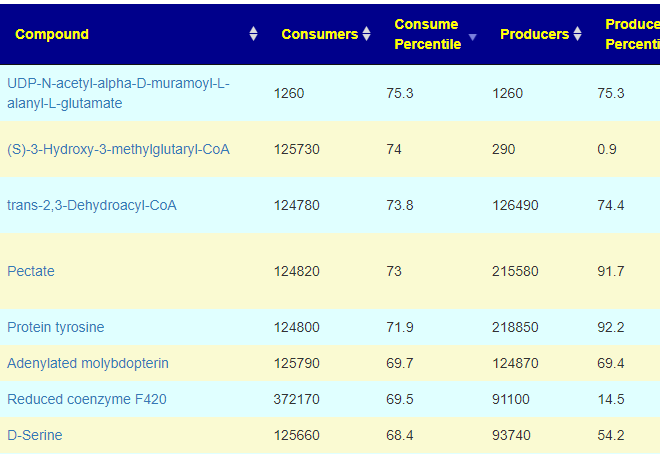
Compounds Produced and Consumed Page
Looking at the new Compounds Produced and Consumed, there were a number of items that had high ( > 99%ile) production – with 600 items listed, we would have expected just 6 (1%) not 41!!:
In terms of consumers, the highest percentile was 75.3%ile, In fact most of the consumed items appear ‘balanced’
Proposed Model
Because events were recent, we have high volatility in the microbiome’s bacteria. I saw similar at the start of my relapse… the various clans of bacteria are fighting each other with short term victors of one group and then a reversal.
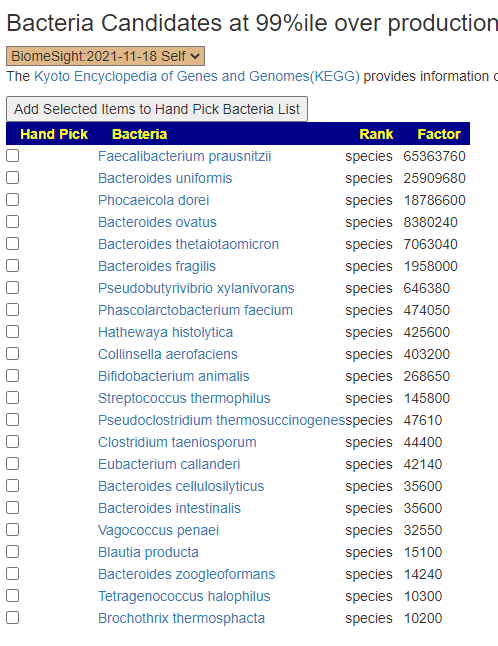
The apparent issue is massive overproduction of compounds!!! How to address that may mean that I need to add more code to identify the key bacteria responsible and thus the page changed as shown below. This is a logical but experimental novel approach.
The result is shown below:
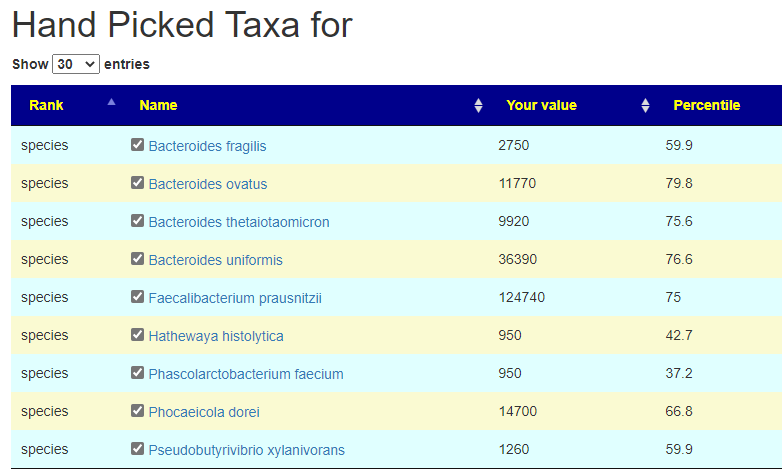
Next I checked the highest numbers to create a Hand Picked list
The result is show below. None were very high by themselves, Five were around 75%ile
I removed everything below 50%
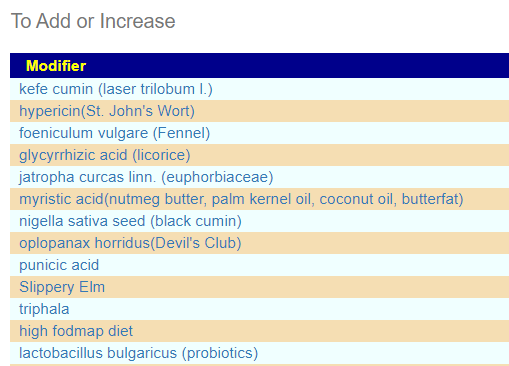
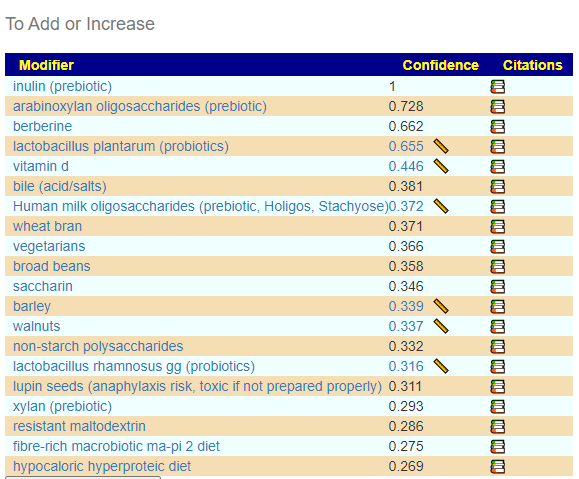
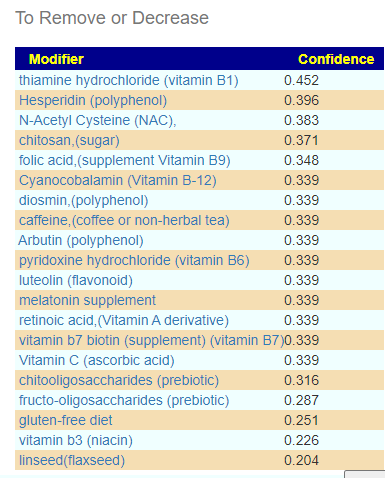
From this hand pick selection, we proceed to get suggestions. The results are shown below
and the to-avoid
This looks similar to what I often see with ME/CFS people. That is, breakfast porridge made from barley with inulin and wheat bran with walnuts (which is my own regular breakfast!) with yogurt containing lactobacillus plantarum. There are some interesting studies in this area:
After getting to this point, the reader reported some recent lab results. Some are of interest:
Vitamin D was just 28% into the normal range, so the vitamin D suggestion above is reasonable
His coagulation factor II (G20210A/G) was at the high end of normal — I have the same coagulation issue and found that turmeric with black pepper or piracetam helps greatly — especially with brain fog and slowness.
Issues causing hypercoagulation (thick blood) was shown to be common with ME/CFS by David Berg back in 1999, for articles and townhall transcripts (hosted by me!) see this page. This appears of part of this person’s causality.
Neither G20210A nor Protein S are likely to be deemed clinically significant, thus my personal preference (regular heparin taken sublingual, held for 1 minute and then spitted out) is unlikely to be prescribed.
Prior to my getting my first COVID vaccine, I had concerns about it triggering coagulation – an ongoing ME/CFS risk. The reason was simple, vaccines triggers an immune reaction — milder than having COVID — but still an immune reaction. COVID was at that time, well known to produce coagulation issues (Abnormal coagulation parameters are associated with poor prognosis in patients with novel coronavirus pneumonia April 2020) so they was a risk. The severity would likely be far less than that of COVID, but still enough to push someone with borderline coagulation issue across into ME/CFS. This appears to be correct as shown by some studies, a few are:
The microbiome is just a part of a health analysis, a significant part but far from being complete. We have a model for the tiredness. IMHO, non-prescription anti-coagulation treatments may eliminate it over a few months.
We are going to do two approaches that are connected.
Coagulation — which appears to be caused by the bacteria of concern (a topic that I cover on CFS Remission)
Bacteria — the ones that appear to be causing over production of many compounds
Reducing some of the bacteria cited above will likely also help, since many are known to cause coagulation:
“These results indicated that Bacteroides sp. and F. mortiferum can accelerate blood coagulation in vivo ” [1973]
“Bacteroides fragilis, Bacteroides vulgatus, and Fusobacterium mortiferum …. demonstrate that LPS of selected gram-negative anaerobes activate HF and thereby initiate the intrinsic pathway of coagulation.” [1984]
Interaction of Bacteroides fragilis and Bacteroides thetaiotaomicron with the kallikrein-kinin system [2011]
“Bacteroides fragilis and Bacteroides thetaiotaomicron, were found to bind HK and fibrinogen, the major clotting protein, “
Unhappy Triad: Infection with Leptospira spp. Escherichia coli and Bacteroides uniformis Associated with an Unusual Manifestation of Portal Vein Thrombosis [2021]
Some questions from reader:
“The only probiotic I will add is lactobacillus plantarum. (Or also lactobacillus rhamnosus gg?) I will have to rotate that. Here is the question: I would also like to address IBS. I read on cfsremission that some probiotics, like Prescript Assist, could lead to IBS remission. Prescript Assist was also 2nd place on the KEGG recommendations, although you said the weights were marginal. Would it be not unreasonable to try Prescript Assist at some point, to address IBS?“
Yes, I would suggest two-four weeks on a probiotic and then rotate to the other
Add: As many of the recommendations as possible from the Kaltoft-Moltrup suggestions, the KEGG recommended supplements, and the novel approach. Add anticoagulants.
After 2 months test again.
Yes, if sound very reasonable – track objective measurements as much as possible
New results IgA 1 is at 4500 with normal range 500-2000. This may be related to the vaccination but IgA is associated with a lot of things.
“Results in the naïve-vaccinated group, the mRNA-1273 vaccine induced significantly higher levels .. of IgA (2.1-fold, P < 0.001) as compared with the BNT162b2 vaccine.” [2021]



Recent Comments