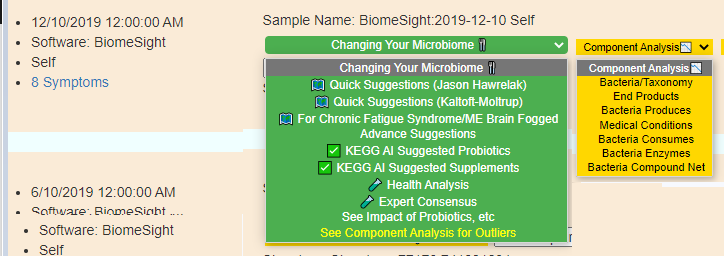
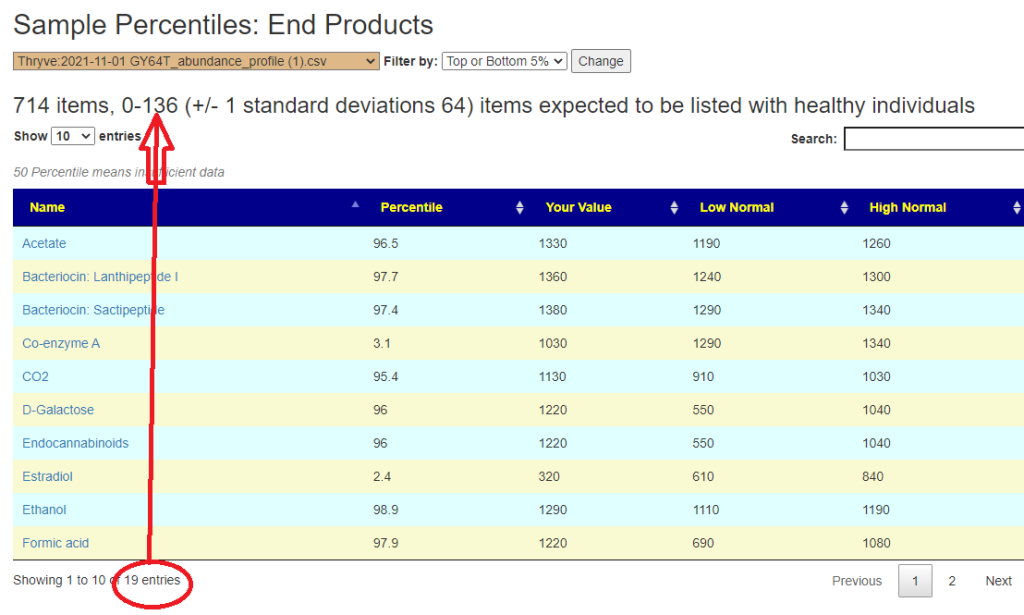
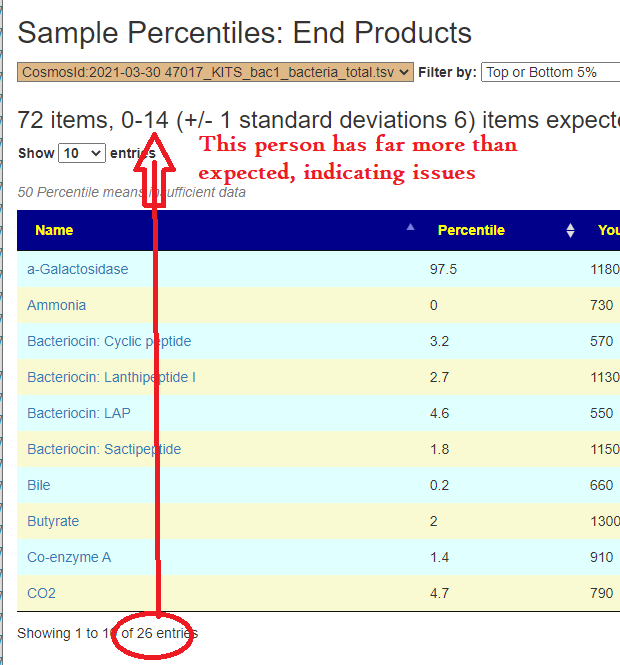
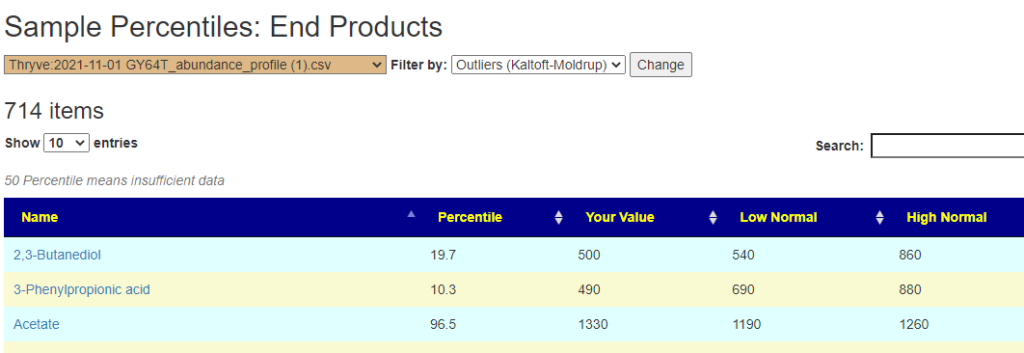
Someone mentions that to me. My initial response is simple… don’t jump to conclusions without supporting lab results. Without lab results, you may feel the same from any of many condition that produces hypoxia (low oxygen delivery). Hyper-coagulation is one possible cause there are others. This is a quick list of items to get objective measures from..
- First, get and monitor your saturated oxygen level. A lot of people have the Fingertip Pulse Oximeters. They are cheap and often under $20. With COVID persisting, they should be in every home first aid kit!
- Both my wife and I wear a watch that records Saturated O2 every 15 minutes and we can view our history on our phone. See this post.
- Both my wife and I wear a watch that records Saturated O2 every 15 minutes and we can view our history on our phone. See this post.

- If you are low, then there can be several possible causes (I will use some automotive analogy):
- Low iron / problems absorbing iron i.e. Low Hemoglobin – low grade of gas
- Vascular constriction: the flow of blood is down, so less oxygen gets there, see Peripheral vasoconstriction influences thenar oxygen saturation as measured by near-infrared spectroscopy [2012] – your gas line is pinched….
- Fibrin deposits slowing blood flow. See The association of oxygen saturation, tomography findings and D-dimer levels in coronavirus disease 2019 patients [2020] – in this the blood is not thick, but “your oil filter is dirty”
- Your blood may be sticky – the term is often used with Hughes Syndrome or antiphospholipid antibody syndrome (APS),
- Your blood may be odd shaped. The most extreme case is sickle cell anemia, but studies with ME/CFS patients have a different form, “So it has been proposed – first at the Cambridge Symposium on ME in 1990 and in another article in 1998, that ME is a dysfunctional state resulting from reduced rates of capillary blood flow due to the presence of shape-changed, poorly-deformable red cells” [source] – From Dr. Les Simpson in New Zealand
- You may have a low red blood cell count. Red blood cells are what carries oxygen
- You may have a low blood volume “In contrast, ME patients have a volume that can be as low as 50% of normal.” from an 2015 update by Dr. Bell
- Small heart size — as you age, it is less able to push blood thru as well. “A considerable number of CFS patients have a small heart. Small heart syndrome may contribute to the development of CFS as a constitutional factor predisposing to fatigue, and may be included in the genesis of CFS.” [2008]
- Also, low blood pressure can come in.
- If it is truly hypercoagulation — there are tests for that (I personally did them) see Hemex’s ISAC Panel for ME/CFS is available. Be warned, that the standard tests do not cover all types of coagulation issues, also, unless the values are truly extreme — most specialists will ignore the results. See Hypercoagulable states: an algorithmic approach to laboratory testing and update on monitoring of direct oral anticoagulants [2014]
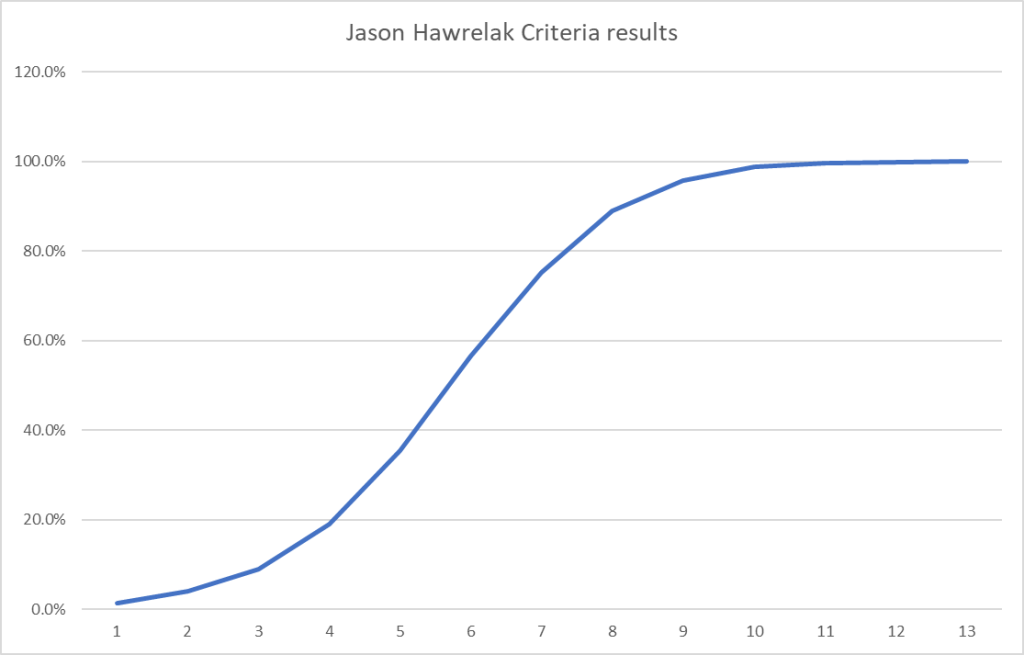
Bottom line: Get lab results when possible and do not speculate. I recall that some supplements will improve certain types of hypercoagulation and make other types worse. Act from objective knowledge and not speculation.








Recent Comments