A reader asked for my opinion on this. This is one of those topics where emotions often run hot and reason can be forgotten. I usually avoid these topics — I hate flame wars.
All of these passion topics, tend to have the following critical factors:
- If those that advocate also sell the product, there is a clear conflict of interest. I will usually assume that their primary motivation is profit that is clothed in the appearance of wanting to help.
- If they do not sell, but often use it, then we have the nasty issue of rose color glasses, selected data picking of their patients. They may have a vested interest in wanting to be right or a pioneer. They usually ignore those that have adverse results (often those people do not return to the people treating — hence they do not see these adverse results or discount them to non-compliance to the treatment plan (blame the patient syndrome).
- Last thing is desperation, especially when standard of medical care fails — people are willing to try anything, regardless of the risk and often very low success (which could have happen at random).
These risks applies to most items where feelings run high.
So, I go over to gold standards sources only (studies published on the US National Library of Medicine aka PubMed).
Helminth and the Microbiome
First item, is that there is risk: “Soil-transmitted helminth infections represent a large burden with over a quarter of the world’s population at risk. Low cure rates are observed with standard of care (albendazole)” [2022]. Hence, viable (living) helminthiases should be avoid. Killed ones (for their chemicals) would be preferred. If things go bad, you are looking at low cure rate!
This study suggests that it could be useful with some gastrointestinal dysbiosis — “Helminth-Induced Human Gastrointestinal Dysbiosis: a Systematic Review and Meta-Analysis Reveals Insights into Altered Taxon Diversity and Microbial Gradient Collapse” [2021], that is two dysbiosis could result in less or more dysbiosis! Dysbiosis roulette anyone?
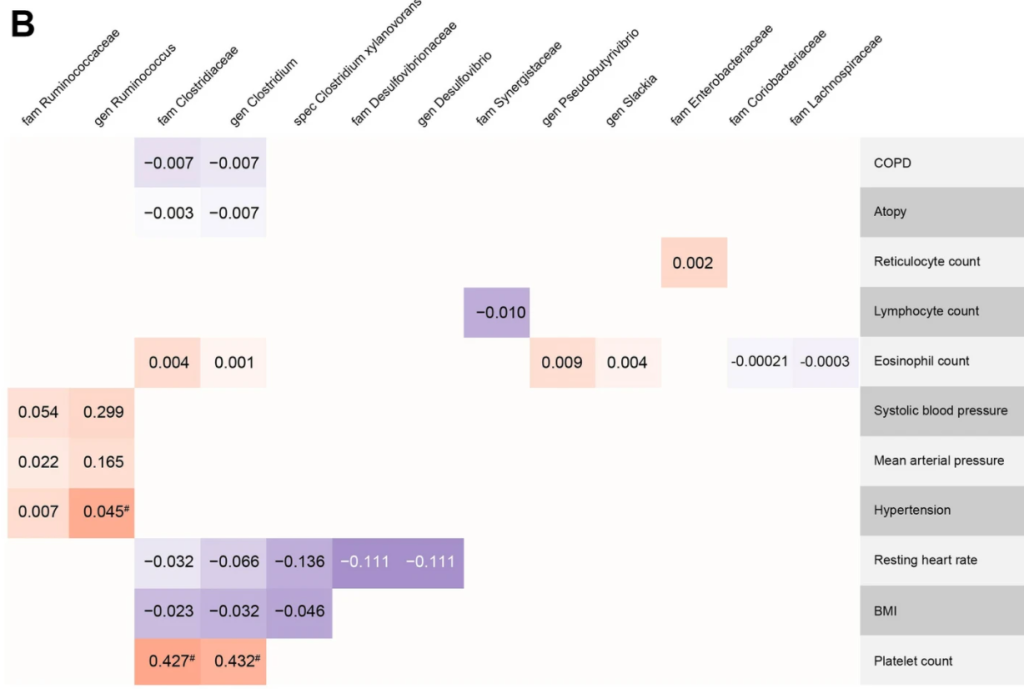
Helminth infection is included in my microbiome modifiers with 130+ bacteria impacted, see this page (I also include Round-Up! To include it in your suggestions, pick “Prescription – Other“. Remember NONE of the modifier suggestions should be done without medical review).
Please note also that if the treatment including killing them afterwards, that treatment alone may be responsible for positive effects
“There was evidence of treatment-specific effects among the selected studies, such as findings of treatment-associated taxa, including Sphingobacteriaceae and Flavobacteriaceae (26); increased and decreased Actinobacteria and Bacteroidetes, respectively, after placebo comparison (18); mebendazole treatment-induced changes in the diversity and abundance of Collinsella and Blautia (27);”
“Helminth-Induced Human Gastrointestinal Dysbiosis: a Systematic Review and Meta-Analysis Reveals Insights into Altered Taxon Diversity and Microbial Gradient Collapse“
Quick Review of an Advocate
The reader referred me to Lindsey Wells, a naturopath, page on Helminth Therapy. The Hygiene Hypothesis of Autoimmunity is cited which I have touched upon in the past 2015, 2018. To me, many advocates of this hypothesis both over simplify and commercialize it. If you wish to take this hypothesis seriously, then there is only one treatments: live on an organic farm, with a lot of different animals — if your boots are not covered in manure, every day — you are not taking the hypothesis seriously!
“The Amish and Hutterites are U.S. agricultural populations whose lifestyles are remarkably similar in many respects but whose farming practices, in particular, are distinct; the former follow traditional farming practices whereas the latter use industrialized farming practices….Despite the similar genetic ancestries and lifestyles of Amish and Hutterite children, the prevalence of asthma and allergic sensitization was 4 and 6 times as low in the Amish” – i.e. industrialized farming practices resulted in six times (600%) the rate of asthma and allergies. See Innate Immunity and Asthma Risk in Amish and Hutterite Farm Children(2016). This is also echoed in their farm products!!! Amish and Hutterite Environmental Farm Products Have Opposite Effects on Experimental Models of Asthma [2016]. Given a choice of buying groceries from a Hutterite farm or a Amish farm, buy the Amish (non industrialized) groceries!!!!
The bottom line of this page is simple — not a single clinical study was cited. The link to https://biomerestoration.com/hdc/ and where I would expect studies (under “The Science”), there was not one.

And the other site cited: https://helminthictherapywiki.org/wiki/index.php/Helminthic_therapy_research had links to a lot of self-published papers (i.e. not peer reviewed) and just 2 on PubMed.
- Practices and outcomes of self-treatment with helminths based on physicians’ observations [2016]
- As I stated at the start, this is among the worst form of study because it is prone to the placebo effect plus discontinuation of patients that are non-responders or who have adverse results. They do mention “1% of paediatric patients experienced severe gastrointestinal pains”. No objective measures (labs, etc) were cited. IMHO, a purely subjective report. Note that the journal that it was published in was Journal of Helminthology (I wonder if there is a bias with those doing peer review?)
- Helminth–host immunological interactions: prevention and control of immune-mediated diseases [2012] Which is more of a position paper that was unable to cite any significant human studies, just case reports (which is prone to the same bias as cited above).
- “Thus, it should come as no surprise that eradicating helminths can result in expression of diseases influenced by these pathways. There are now many animal models representing a diverse range of diseases for which helminths either prevent and/or reverse ongoing pathology. “
And now for Autism
- Helminth therapy for autism under gut-brain axis- hypothesis. [2019] which is a theoretical proposal without any clinical results. It was published in the Med Hypotheses Journal.
- “I hypothesized that a treatment with Trichuris suis soluble products represents a feasible holistic treatment for autism, and the key for the development of novel treatments. Preclinical studies are required to test this hypothesis.”
Bottom line: there are no clinical studies supporting it use for autism, it is all theoretical. Microbiome Prescription does include it in the options of gut modifiers — so you can objectively see if it is a good fit for an autistic child’s microbiome.
A Critical Criteria: If something has been proposed for 5+ years and fail to produce a positive clinical study then assume there have been several studies done with no positive results.
To me, it is not a rational choice — significant risk of known demonstrated adverse issues with no significant demonstrated positive impact. Odds are that going camping for 2 months in the woods will have a greater positive impact, or better still, work on an organic farm tending chickens, pigs and shoveling manure! Getting involved with 4H may be a good thing in many ways!




Recent Comments