Ranges are created by labs to be able to give answers to people asking for them. The key word is created. They may have no actually be healthy ranges for your age, gender, diet style etc. Say again! Not actually healthy ranges for you.
At the highest levels of the bacteria are phylums: (Firmicutes and Bacteroidetes). Almost every bacteria belongs to one of these two phylums. Almost every person in the US would be unhealthy by Indian Standards — well outside of the typical ranges. And almost every person in the India would be unhealthy by US Standards — well outside of the typical ranges. If you are of Indian descent living in the U.S. and eating a mixture of Indian and Western foods… any ideas of what you healthy range should be?
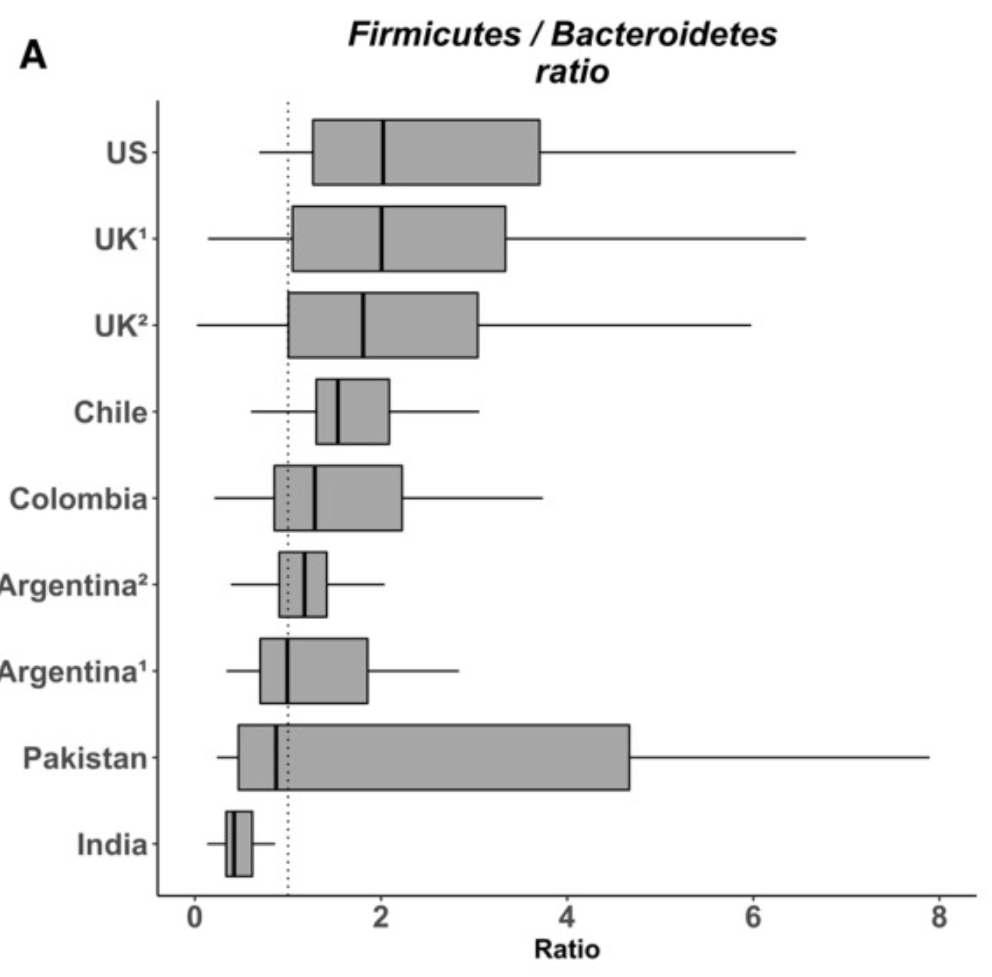
The classic approach in most labs for other tests (like Vitamin D, iron, etc) is to get a collection of apparently healthy individuals from physically around where the lab is and the assume that the data will be a bell curve/normal distribution. The people are typically self-declared to be healthy – for Americans, this will usually be high in people that have a high body-mass index [BI] (i.e. overweight). We know that a high BI causes changes in the microbiome…. From that data, compute the range — see typical instructions to labs here: Standard Lab Ranges (+/- 2 Standard Deviations). This assumption is never validated statistically on the data – lack of appropriate skills in the lab is a common cause. If you attempt to validate against almost any bacteria in the microbiome — it will fail, often extremely fail.
Research scientists knows that this is making a huge assumption and will often in their research papers use a method called Box Plot Whisker. It is definitely better but typically require more samples to establish the ranges. A lab manager will opt not to do it when he may only need to do 30 samples to get the Standard Lab Ranges, and may need 150 samples to get a good Box Plot Whisker. Why should he want to increase costs when he can go cheap and claim that he is following standard processes.
Wait! There is More!
Suppose that you get 200 “healthy samples” — we can get the ranges using Box Plot Whisker and that’s it! We now know what healthy ranges are then!!!
WRONG!!! VERY WRONG!!! The National Institute of Standards and Technology (the same people who define how long a foot is, or how many lumens a light bulb has) has made if very clear!!!!
If we have 200 samples, we will likely have 97 different ranges!!

Some of the ranges from different ways will be in significant contrast with each. To illustrate this, let us look at samples uploaded from OmbreLabs and Biomesight — they both use the same physical lab that has the same equipment — the difference is the software (“the ways”) that they use on the identically same data file!!!! We are NOT talking about two samples from the same stool; we are talking about one sample only
| Lab | Bacteria/Taxa Types |
| BiomeSight | 4193 |
| OmbreLabs | 6549 |
| uBiome | 2324 |
Looking at frequency of detection, we have some good matches at the genus level
| Tax_Name | BiomeSight % Detected | OmbreLabs % Detected | BiomeSight Average % | OmbreLabs Average % |
| Vibrio | 3.888 | 3.907 | 0.003 | 0.003 |
| Nitrobacter | 0.299 | 0.319 | 0.002 | 0.002 |
| Prochlorococcus | 0.179 | 0.159 | 0.003 | 0.003 |
| Ruegeria | 0.179 | 0.159 | 0.001 | 0.004 |
And some bad ones!
| Tax_Name | BiomeSight % Detected | OmbreLabs % Detected | BiomeSight Average % | OmbreLabs Average % |
| Rhodothermus | 90.371 | 1.914 | 0.275 | 0.039 |
| Escherichia | 80.742 | 5.183 | 0.536 | 0.058 |
| Pedobacter | 97.967 | 24.083 | 0.936 | 0.014 |
| Alkaliphilus | 97.189 | 28.628 | 0.348 | 0.011 |
Whose right? Both are right and both are wrong — there is no standard!!!! Right assumes a shared upon norm or consensus by people concerned.
What is my personal solution?
I am by academics and industrial experience, a statistician, operational research and Artificial Intelligence Software Engineer. The way to get the most probable solution from a difference of opinions, is to build a consensus model — take every ones suggestions and combined them!
At present I have good number of opinions that can be used, and if I get more expert opinions (and permission to use them) I will gladly add them.
I would love to see all of the labs make public the data they used to construct their ranges. Open data. I have discussed that with some of them and they deem it to be “proprietary” data. It is, in that the disclosure may reveal their mistakes and expose their ranges as questionable. Every one’s ranges are questionable (IMHO).
There is no right answer. There is no trustworthy range. A consensus answer is likely a good answer, the best that is available at the moment.
1 thought on “The problem with “official” ranges from labs”
Comments are closed.